
Reverse Knowledge Distillation for Retinal Image Matching (WACV 2024)
Date:
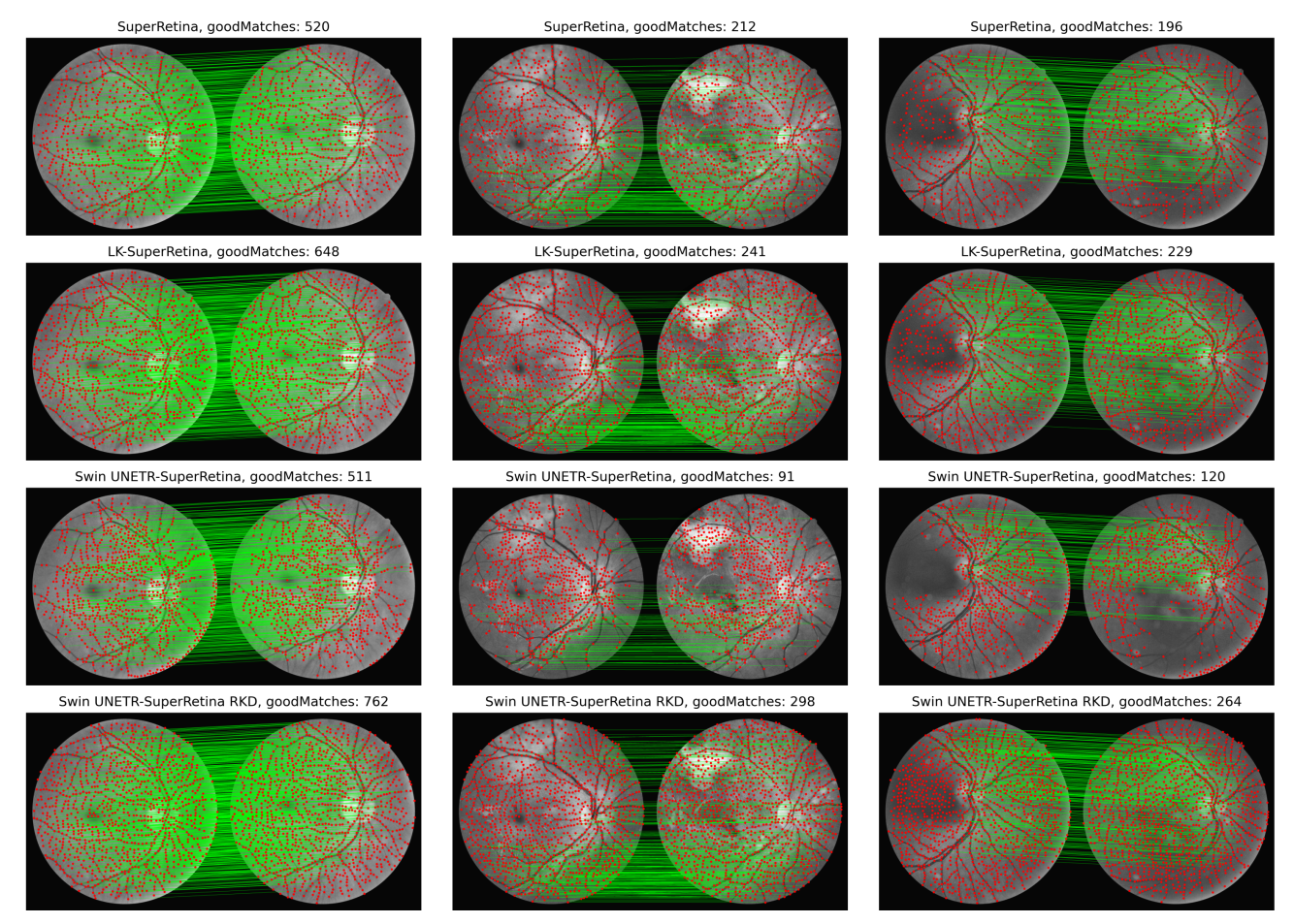
I presented our paper “Reverse Knowledge Distillation: Training a Large Model Using a Small One for Retinal Image Matching on Limited Data” at WACV 2024.
This work achieved state-of-the-art performance for retinal image registration by leveraging knowledge transfer from a small to a large model.
Abstract
We introduce a reverse knowledge distillation framework where a large model is trained using the supervision of a smaller, well-regularized model on limited data. This enables improved generalization and robustness in retinal image matching.
The proposed method outperformed existing approaches across benchmark datasets.